Tra le tante definizioni di machine learning quella che preferisco è stata data da uno dei più importanti computer scientist viventi Tom Mitchell, professore al Carnegie Mellon University a Pittsburgh, che lo definisce come “un programma informatico che apprende dall’esperienza E con riferimento a qualche classe di compiti con performance P in modo tale che le sue performance nello svolgere il compito T, misurato da P, migliora con l’esperienza E“. Trovo questa definizione particolarmente adatta anche a definire il percorso di apprendimento che segue qualunque essere umano a partire dal parto e forse, come si è scoperto da poco, anche qualche tempo prima durante tutta la fase di gestazione.
Tra le tante definizioni di machine learning quella che preferisco è stata data da uno dei più importanti computer scientist viventi Tom Mitchell, professore al Carnegie Mellon University a Pittsburgh, che lo definisce come “un programma informatico che apprende dall’esperienza E con riferimento a qualche classe di compiti con performance P in modo tale che le sue performance nello svolgere il compito T, misurato da P, migliora con l’esperienza E“. Trovo questa definizione particolarmente adatta anche a definire il percorso di apprendimento che segue qualunque essere umano a partire dal parto e forse, come si è scoperto da poco, anche qualche tempo prima durante tutta la fase di gestazione.

Il punto sicuramente cruciale che ha portato all’evoluzione degli ultimi 15 anni del machine learning è stato come siamo riusciti a trasferire l’esperienza E ai programmi informatici. La digitalizzazione, la facilità (economicità tecnologica) di raccogliere dati e la contribuzione di massa (Web 2.0) hanno consentito di avere una quantità impressionante di esperienze facilmente utilizzabili dai computer. Chiaramente facendo un parallelismo tra l’apprendimento del uomo e quella della macchina esistono ancora grandissimi vantaggi a favore dell’uomo poichè siamo ancora lontani dal riuscire a codificare ad un sistema informatico la ricchezza dell’esperienza umana (fattore E). Ma il gap si sta comunque riducendo grazie all’evoluzioni recentissime del deep learning e del reinforcement learning che sono riusciti a migliorare moltissimo su aspetti quali la visione, l’elaborazione di un testo (es: problema della traduzione) e anche la strategia. Gli aspetti dove invece i sistemi non umani ci stanno superando sono la capacità elaborativa di questa esperienza sia per la legge di Moore sia per l’evoluzioni delle architetture deputate a questo tipo di elaborazione (evoluzioni dei sistemi a GPU in primis). Inoltre la continuità di energia a disposizione (i computer non dormono …) è un fattore fortemente a vantaggio di un sistema che non si è evoluto in miliardi di anni ma è stato progettato in pochi decenni.
Non dimentichiamoci che è comunque l’uomo a guidare l’evoluzione di questi sistemi ed è fondamentale che ne comprenda a pieno il loro funzionamento sia per continuare a guidare sia per coglierne benefici di massa.
In questo senso credo siano cruciali alcuni aspetti che vanno gestiti con consapevolezza sempre più allargata. Provo ad elencarne alcuni in maniera non esaustiva:
- La logica di funzionamento dei sistemi di machine learning vanno capiti da un numero sempre più vasto di individui e di aziende perchè solo dalla loro conoscenza può scaturire l’elaborazione di domande e quindi di soluzioni a beneficio della collettività e non di oligopoli di individui (nerd) o di aziende (big tech companies). E su questo l’educazione di massa, soprattutto delle nuove generazioni, è il fattore più strategico.
- Per favorire il punto 1 i principali algoritmi, tecniche e strumenti che ruotano attorno al machine learning devono essere il più possibile Open. Esperimenti quali OpenAi vanno in questo senso ma andrebbero ulteriormente incentivati e allargati.
- Andrebbe sfavorito l’accentramento di oligopoli di dati non tanto con politiche protezionistiche nazionali o restrittive nei confronti delle aziende detentrici degli stessi ma con politiche che favoriscano la valorizzazione dei dati individuali e con l’allargamento dell’utilizzo degli stessi da parte di nuove organizzazioni attraverso l’eliminazione di barriere anche tecnologiche (formati non standard) al loro scambio. In questo senso politiche eccessivamente conservatrici nella protezione dei dati individuali finiscono per favorire gli oligolipoli sfavorendo ulteriormente l’individuo/consumatore.
- Politiche fortemente diverse tra stati nella regolamentazione di un fenomeno così globale quale il machine learning potrebbero portare ad aumentare ulteriormente la differenza di produttività e reddito in differenti aree del pianeta. Non essendo possibile, in senso realistico, accordi internazionali globali ritengo che sia fondamentale che ogni stato nazionali adotti politiche molto “agili” e sperimentatrici ma vigili in ambito legale per evitare di avere gap difficilmente colmabili.
La sfida per tutta l’umanità resta complessa e non facilmente indirizzabile. Tuttavia sono convinto che solo consapevolezza, investimenti in educazione specifica e una regolamentazione leggera lontana dalla burocrazia possano mantenere “umana” la guida di questo fenomeno che non investe solo la tecnologia ma anche e soprattutto l’economia e l’etica.











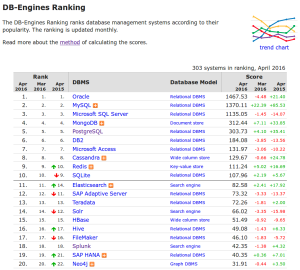
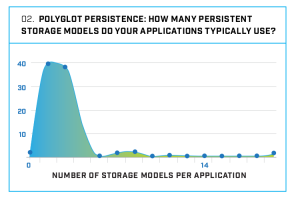 in una recente indagine, condotta a livello mondiale sul numero di sistemi di persistenza dati usati all’interno della stessa applicazione il numero due è appaiato con il 38% all’uno con il 40%. Ormai più del 50% delle applicazioni usano più di un sistema di persistenza dati! Con ormai oltre 150 sistemi di gestione dati con una importanza e diffusione rilevante (assumendo come soglia lo score 0.50 della classifica di
in una recente indagine, condotta a livello mondiale sul numero di sistemi di persistenza dati usati all’interno della stessa applicazione il numero due è appaiato con il 38% all’uno con il 40%. Ormai più del 50% delle applicazioni usano più di un sistema di persistenza dati! Con ormai oltre 150 sistemi di gestione dati con una importanza e diffusione rilevante (assumendo come soglia lo score 0.50 della classifica di  Nel libro Bodei, raccontando come nella storia dell’uomo il concetto di limite abbia avuto differenti interpretazioni, arriva a riflettere su come il suo superamento sia diventato, in moltissime discipline, una caratteristica della società moderna. Ma non è sempre stato così: a lungo le innovazioni tecnologiche e la creatività sono state viste con sospetto o considerate nocive. Si parte nel mondo greco-romano dalla frase “Niente di troppo” sul muro esterno del tempio di Apollo a Delfi, al mito di Icaro per passare all’artigiano che sotto Tiberio inventò il vetro infrangibile ma che fu decapitato per la paura che il suo uso facesse deprezzare l’oro. Ma forse il caso più “attuale” fu quello di Vespasiano che premiò l’inventore di una macchina per spostare grandi pesi in campo edilizio, ma che ne vietò la diffusione per non togliere lavoro alla sua plebicula. Riuscite forse ad immaginare qualcosa di simile oggi? Per esempio la proibizione dell’uso di algoritmi, di intelligenza artificiale o della robotica per difendere l’occupazione degli strati meno istruiti della popolazione mondiale?
Nel libro Bodei, raccontando come nella storia dell’uomo il concetto di limite abbia avuto differenti interpretazioni, arriva a riflettere su come il suo superamento sia diventato, in moltissime discipline, una caratteristica della società moderna. Ma non è sempre stato così: a lungo le innovazioni tecnologiche e la creatività sono state viste con sospetto o considerate nocive. Si parte nel mondo greco-romano dalla frase “Niente di troppo” sul muro esterno del tempio di Apollo a Delfi, al mito di Icaro per passare all’artigiano che sotto Tiberio inventò il vetro infrangibile ma che fu decapitato per la paura che il suo uso facesse deprezzare l’oro. Ma forse il caso più “attuale” fu quello di Vespasiano che premiò l’inventore di una macchina per spostare grandi pesi in campo edilizio, ma che ne vietò la diffusione per non togliere lavoro alla sua plebicula. Riuscite forse ad immaginare qualcosa di simile oggi? Per esempio la proibizione dell’uso di algoritmi, di intelligenza artificiale o della robotica per difendere l’occupazione degli strati meno istruiti della popolazione mondiale?